

The Embedded Recipes conference is a small but highly influential annual event, attracting around 100 attendees and featuring a single-track program in one room. Its relaxed and informal atmosphere encourages meaningful and spontaneous interactions among participants.
This article is the first of two, distilling the key takeaways from the event, summarizing core technical insights and highlighting emerging trends in the Linux kernel and embedded systems communities.
Below you will find summaries of the talks as a guide to decide which ones you may want to explore in full. The links to the videos and slides are provided for each.
The CRA and what it means for us
Greg Kroah-Hartman, Linux Foundation
This talk was an excellent introduction to the Cyber Resilience Act (CRA) and its significance for open source software developers. Short and sweet! You will not learn much about what it means for you as a developer of an embedded product, but it is relevant if you have any open source software development activities. The many questions of the audience shows the importance of the CRA to open source software and its communities.
The text below is not so much a summary of the presentation, but rather an attempt to bring the same content, in its entirety, in written form.
Greg is the Linux kernel’s maintainer for stable branches. He is also responsible in the Linux CNA, i.e. reporting vulnerabilities (CVEs) for the kernel and is a member of the CRA expert group that defines standards and processes to make implementing the CRA possible.
The Cyber Resilience Act (CRA) is an EU regulation that came into force at the end of 2024 to regulate the security of products containing software. The obligations stemming from it gradually start applying on September 11, 2026, until it applies entirely on December 11, 2027.
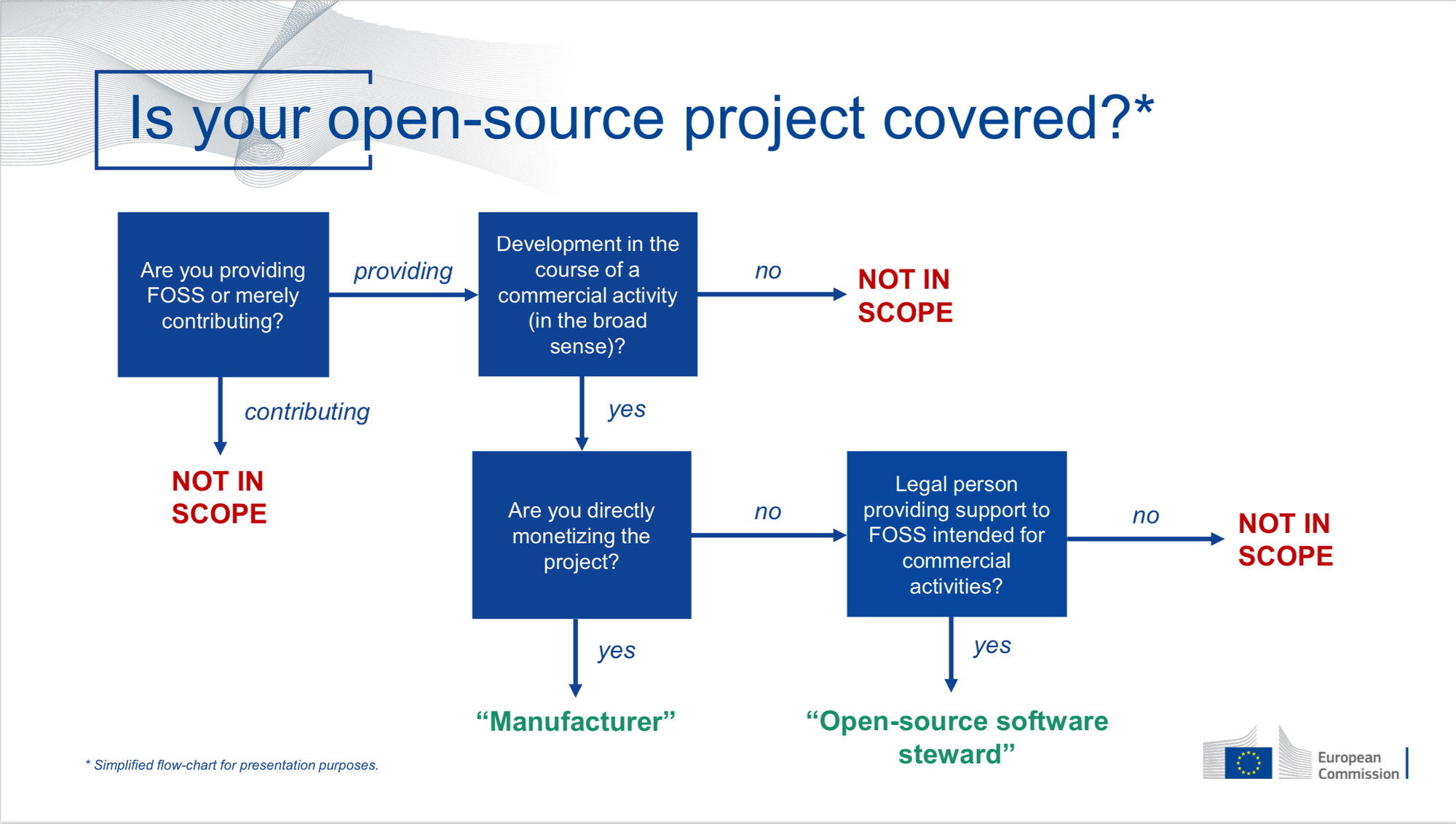
The core concept of the CRA is a Product with Digital Elements (PDE). This is anything which has software in it (including software itself, but not services, because there’s a separate regulation for those) and that is “brought to the market”. It is a concern for Open Source Software (OSS) developers, because “bringing to the market” includes any form of making it available to people in Europe, even if it is given away for free. Fortunately, thanks to lobby work, the CRA has explicit provisions for OSS. This talk focuses on the impact the CRA has on OSS developers.
The CRA creates obligations for manufacturers, distributors and importers of PDEs. If you develop software, you can be considered a manufacturer. The CRA creates three categories: manufacturer, Open Source Software steward, and out of scope. People have made flow charts to clarify this. The idea is to keep open source software hobbyists free of obligations. This includes when you contribute to software that is not “under your own responsibility”, so none of the companies that contribute to the Linux kernel are considered to be its manufacturers. A special role is created for Open Source Software steward: that is an organisation that receives money from others who are manufacturers of PDEs and under whose responsibility the software is, but that doesn’t itself directly monetise the product. So the Linux Foundation is a steward for the Linux kernel. (Note: there was some confusion about “legal person” - Greg thought this meant a natural person, but it’s actually the other way round, only an organisation can be a steward, not an individual.) A steward does have obligations, but they are much more limited that the obligations of a manufacturer.
The CRA also defines “market surveillance and enforcement” entities, i.e. organisations that are responsible for making sure that the CRA is followed. There is an overarching organisation, ENISA (EU Agency for Cybersecurity), but also many national and supra-national organisations, often multiple per country.
The CRA defines standards, requirements about how to do risk management, design, development and production. These standards will not be finished by the time the CRA goes in force, but they are anyway only advisory, not obligatory. An expert group (of which Greg is a member) defines these.
CRA categorizes products into levels according to how critical they are, i.e. how bad it is if something goes wrong. That obviously depends on the (intended) use of the product, so for OSS it does not really matter because in general it can be used for all product levels.
Some things are outside of the CRA scope: services, products that have specific regulations (automotive, medial, aeronautical, marine, …), and non-commercial hobby products. For OSS, as soon as it becomes part of a product, it does become relevant, but it is the person who puts it in the product who carries obligations (i.e. manufacturer).
A steward has two responsibilities:
- Provide a security contact. When a manufacturer finds a vulnerability, they have to report it to you and to the EU. They can provide patches but you are not obliged to accept them.
- If you do fix something security related, you have to report it to the designated Cyber Security Incident Response Teams (CSIRT) - but it is not yet defined who they are and how vulnerabilities should be reported.
If you are not maintaining the software any longer, you do not have to do anything, you do not even need the contact address any more. Basically, you are no longer an open source steward. The manufacturers still have that responsibility, they still need to maintain their product that uses your software, report and fix vulnerabilities. MITRE is in fact working on a way to track software that is abandoned, to block new CVEs from being reported on it.
Concretely, Greg’s advice is that a steward (but any maintainer of a project, really) should do the following:
- Include a
security.txtfile in the source, with contact details for reporting vulnerabilities. - Become a CNA or fill out a form to indicate who is responsible for vulnerabilities.
- Follow https://bestpractices.dev/
- Use the REUSE tool of FSFE.
The Open Source Security Foundation (OpenSSF) has has a CRA checklist for steward.
For CRA obligations in general, including what it means for manufacturers using OSS and for individual developers, there are many resources. The Linux Foundation has a CRA site and a training course. OpenSSF also has a CRA site - they are generally better. And finally, there is also the official ENISA documentation.
Elephants in our embedded security room
Marta Rybczynska, Ygreky
Marta is a consultant giving training and advice to companies making embedded products, mostly around security. In this talk she offers some observations about how products are typically created and how to improve that. There are no big surprises, but it’s great to see everything put together.
Open source software is a major success, present in nearly all modern (embedded) products. However, it is often perceived as being free of cost and the applicable licenses are typically the only factor considered when choosing open source components for use in a product, while long-term maintenance costs are usually ignored. Moreover, internal company cultures create barriers to collaborating with upstream communities, increasing the maintenance burden for the company.
In the past, at least, embedded products were typically based on custom hardware designs and integrated many in-house software components. Today, however, they increasingly integrate a range of off-the-shelf hardware and software components.
Marta gives the following advice to creators of embedded systems containing open source components.
First, make sure it is possible to do software updates. This may require a change in hardware to be able to support it. Second, don’t blindly integrate software, but review your dependencies. Don’t just look at the license, but also to the maintainability. If a component does not have a reliable upstream, you either have to be willing to maintain it yourself, or you have to look for something else. Third, have a policy of updating your dependencies, do not just react to CVEs. Some packages do not bother with CVEs so lack of CVEs does not mean your security is OK. Since not all packages have a long-term support strategy, this affects the maintenance cost. You have to account for API changes that require updates to other components in the system. Finally, include security mitigations in your product requirements.
Persistent Shutdown Reasons & Hardware Protection: Making Embedded Systems More Resilient
Oleksij Rempel, Pengutronix
Oleksij is a kernel developer at Pengutronix. He typically works at the board level with limited idea of how the hardware is used in the final product or how the product actually works. His usual focus is on making things work, but his current efforts are aimed at ensuring they fail more gracefully if and when they fail. This talk is a report from the trenches about Oleksij’s specific experiences, but the learnings can be applied in many other situations.
When there is a problem with a product that affects the users, the report you get from the user is often very far away from the root cause, making it extremely hard to find that root cause. It is therefore important to build in observability into the product, so that when something comes back as “broken”, there is some information for you to narrow down the possible causes.
Traditional logging tends to fail because the interesting logs never made it to flash. And if the problem results in flash corruption you have nothing. An example that Oleksij encountered is that there was a spike in current draw that caused a voltage drop that caused eMMC to fail. To be able to find this, you need a detector (under-voltage) that triggers a reaction (reduce current draw immediately) and that records the problem. So you usually need hardware support to be able to detect this type of problem.
As a first step, Oleksij added an under-voltage detector in the regulator framework. This is a GPIO line coming from the regulator - he only implemented it for the fixed regulator. The GPIO is configured as an interrupt and triggers under-voltage handling in the kernel. This signal is propagated to consumers of the regulator. The second step is implementing a handler in the MMC framework. It sends a notification to the driver. The MMC drivers sends EXT_CSD_POWER_OFF_SHORT to the device, which tells it to stop all activity.
Although the actions to take are somewhat use case specific, there are indeed some generic things that the kernel can do. For example, it is possible to calculate based on the available capacitance how many milliseconds of power are left, and based on that to still flush filesystem caches or not.
For recording, Oleksij uses a Power State Change Reason Recording (PSCRR) chip. This is a very small battery-backed FIFO NVRAM. He is upstreaming a framework for it. It has the usual split in framework and driver, only NVMEM is implemented. The idea is to perhaps use the same framework for read-only things, like e.g. the reset reason, or events recorded in a PMIC.
The regulator framework has a new property, regulator-system-critical, which indicates that this regulator is critical and that the kernel needs to take measures (e.g. shut down) if there is a problem with it.
There were a lot of questions from the audience about the practical usability of these ideas in different circumstances. The future will have to show how they can be adapted for more use cases.
PipeWire and Bluetooth: the road to LE Audio
George Kiagiadakis, Collabora
This talk offers technical insight in how Bluetooth LE Audio works, and what it implies for supporting this feature, particularly in PireWire.
Bluetooth is defined (1) by a Core Specification, which outlines its fundamental functionality, and (2) by Profiles, which are higher-level protocols that describe how to use the core features. Although Profiles are versioned and released separately, they are typically published at the same time as the Core Specification.
Bluetooth was initially intended as a wireless serial cable. Started by Ericsson, it focused on mobile phone use cases. Thus, the Headset and Hands-Free Profiles (HSP and HFP) were one of the first profiles to come out. They use a SCO link (synchronous connection-oriented). SCO uses reserved time slots. The other very old profile is Radio Frequency Communication (RFCOMM), which is serial over Bluetooth and was initially used for modems.
HSP and HFP are very similar. Mainly, HFP has more control features to dial numbers, do three-way calls, connect to voice assistant. The profiles defines one codec that always needs to be supported, and additional optional codecs. With the newer codecs (SWB, Super Wide Band) you can get good audio quality.
Later, because of the bad quality of HSP audio, the Advanced Audio Distribution Profile (A2DP) was introduced for high-quality audio. This does not use SCO but the normal best-effort connection, which has higher bandwidth available. Controls were added to it. However, it was intended for media playback so the audio can only go from source to sink. It specifies many different codecs.
Most headsets nowadays support both A2DP and HFP. The effect is that when you get an incoming call, it switches to HFP that is optimized for speech and thus does not do music very well. It is also very power consuming. Because of these shortcomings, vendors (e.g. Apple) have implemented hacks. For instance: for fully wireless earbuds, the source sends the audio stream to only one of them, and that one has to transmit to the other earbud.
To solve these problems, the Bluetooth SIG has developed new core specs and profiles for audio over BLE (LE-Audio). BLE is a different protocol than Bluetooth Classic, but both Bluetooth Classic and BLE are typically implemented in the same controller. BLE was initially intended for wearables ; nowadays, it is used for everything. The new core spec features allow for lower latency (20ms) with better range, at the expense of latency. The profiles use a new codec that has both better quality and lower bandwidth.
The actual audio streaming follows the Basic Audio Profile (BAP), plus a number of control profiles (e.g. Media Control Profile for play, pause, rewind; Call Control Profile, Volume Control Profile). The Common Audio Profile and others are collections of those specifications for specific use cases.
BlueZ and PipeWire support A2DP with many codecs, even some that implement hacks to get a bi-directional over A2DP (though that only works with another PipeWire, not with off-the-shelf devices). They also support HSP/HFP with some of those codecs, and a few backends for the control cards. PipeWire has telephony support in the native backend, so you can send telephony commands over D-Bus to PipeWire and it will send them to the phone. It also supports the phone/modem side of it. Audio Streaming for Hearing Aids (ASHA) is a BLE standard hack that is used for hearing aids. It predates LE-Audio but many hearing aids support it, and PipeWire supports it as well. BLE MIDI is also supported, for both sides. PipeWire also supports the various LE-Audio profiles, but e.g. Broadcast Audio is still incomplete and experimental. There is a problem with headsets that support both A2DP and LE-Audio, because there is no spec to negotiate between the two. So the way to get LE-Audio with such a device currently is to disable A2DP completely in PipeWire, then it will connect to LE-Audio.
The PipeWire developers are considering options to get Rust into PipeWire, either supporting plugins written in Rust, or writing some parts of core in Rust. This, and many other things, will be discussed in the Friday workshop.
Some chips implement the audio codec, so you can offload the codec processing to the Bluetooth controller and just stream raw audio. PipeWire supports this for HFP -where it is more common-, but not for A2DP.
Flicker-free transition of display context across various stages from bootloader to user-space
Devarsh Thakkar, Texas Instruments
When a system with a display boots, it is common to see the screen flicker, turn off multiple times, and even occasionally show corrupted pixels. This behavior has two root causes: framebuffer memory overwrites during initialization and inconsistent state transitions (such as resets) across components in the display pipeline (e.g. backlight, bridge chips, clock domains).
The goal is to be able to display something on the screen as soon as possible, and to preserve it as much as possible during the boot flow without flickering or other artifacts. Even better is to have an animation that can continue while the kernel is booting.
For the bootloader:
- There is a “bloblist” that can be specified of memory areas that have to be preserved between SPL and U-Boot proper. This must be enabled both in SPL and U-Boot.
- Configure U-Boot to leave the power domain of the display on (do not reset it).
The same must be done for the kernel.
- Reserve the framebuffer with a
reserved-memorynode. - Mark the power and clock domains as already-enabled.
- Animations are supported by simple-framebuffer. This works while the display driver is not yet probed. Userspace (psplash) can access it as
/dev/fb0.
Since you do not want to provide those addresses in the device tree source, it can be added in the device tree by U-Boot.
Another issue is that the kernel enables a power domain just before the corresponding is probed, and then disables it again when probing fails. In practice, probing often does fail because there is some dependent driver that is not yet probed (i.e. it fails with defer). Then the power is turned off again. Fortunately, simple-framebuffer helps here because it keeps a reference to the power domain. Patches have been posted to be able to keep power domains on even when simplefb is not used.
simple-drm is similar to simplefb that it uses the reserved memory and makes it available to userspace. It offers /dev/dri/cardX but also has framebuffer emulation with /dev/fb0. However, this uses a new memory buffer to be able to do atomic commit. In order to avoid a black screen, this area must be initialized with the data from the old framebuffer before switching.
All the drivers involved in the display pipeline have to check if they are already active while probing, and not do a reset in that case. So the display is only reset when a new mode setting request comes.
Keeping the power domains on turns out not to be so simple. You need to query the state of all the power domains, and if they are controlled by a separate chip or microcontroller, this can take significant time. One solution is to be able to query state of multiple domains in one query.
The same problems also exist for other peripherals, e.g. a welcome tune that keeps playing during bootloader and kernel boot. So a generic state sync solution is relevant.
It also helps with boot time optimization, because you avoid initializing blocks twice.
Another use case is to ensure smooth transition by having the animation implemented on a separate MCU and hand over to Linux when Weston starts. MCUs generally boot a lot faster than the application processor. To ensure smooth hand-off, you need an IPC mechanism to hand off from the MCU to the Linux display driver.
A problem with reserved memory is that you cannot free it any more, while it is unused once simple-drm or full drm switches to allocated memory buffers.
There is still flicker when Weston starts. This is probably because Weston does a modeset before filling its framebuffer.
Functional Safety and Linux
Maxime Ripard, Red Hat
Back in the 80s, a car had basically no electronics. Nowadays, a car contains thousands of controllers, with very flexible software. And customers demand more and more of it. Some of the software is critical, like brake, airbag, etc., while other software is just for comfort, like the radio, and there are intermediate levels. The industry is moving to fewer processors doing more things at the same time. This is due to chip shortages, because the software has to be updated and that is much easier if there is just a single computer, and it is cheaper so margins are better. This integration implies one chip will run different applications with different criticality levels.
ISO26262 is the standard for functional safety in road vehicles. It is not actually mandatory but everyone follows it. “Functional” means that it is about the controllers, not about the physical aspects. E.g. for an airbag it is not about the materials and size, but rather that it triggers at the correct time.
ISO26262 introduces risk levels and associates requirements with each level. The levels are based on the severity of the effect (S0 = no injuries, S3 = life-threatening), exposure or how likely it is to happen (E0 = very unlikely, E4 = highly likely) and control by the driver (C0 = driver is in full control, C3 = driver cannot influence it). The combination of the three gives ASIL levels, from ASIL-D to ASIL-A. Below ASIL-A is “Quality Managed” i.e. you have to use normal software development practices but nothing in addition. Examples of the levels:
- ASIL-D: total loss of braking;
- ASIL-C: loss of rear braking;
- ASIL-B: loss of brake lights;
- ASIL-A: loss of tail lights;
- QM: weather app on the dashboard.
ASIL-C and ASIL-D recommend formal methods and require verification and validation. Below ASIL-C, the development is much less constrained so getting certified is doable.
An important concept is Freedom From Interference (FFI): a failure in one part must not cascade into other components, especially those with a higher ASIL. There are 3 types of interferences:
- spatial interferences affect the memory of another task,
- temporal interferences take away CPU time, and
- resource interferences cause a dip in the power supply, e.g.
This concept falls nicely in the age-old concept of CPU and memory isolation. Solutions vary from process sandboxing over VMs to fully separate processor cores or chips. Right now, we use a certified hypervisor that runs VMs at different levels. Currently, you can run Linux in a QM VM. In principle, it should be possible to use the scheduler, user space isolation, and resource partitioning, controlled by cgroups, to guarantee FFI.
To get ASIL certification, you have to show an authority that the system design is robust, that it does not have gaps, that the implementation is reviewed, tested and documented, and that you have processes to continue doing this. The authority then gives you a certification for a specific version, you have to repeat it when you want to do updates. Of course, the following iterations are much easier to prove, because you can focus on the differences.
In practice, a few roadblocks are still on the way to certify Linux. There is some breakage of FFI:
- userspace buffer allocation APIs allow spatial interference;
- GPU scheduling can allow temporal interference;
- clock framework changes can also break it.
There are also missing features. E.g. for a dashboard, it is important to still be able to display something when the compositor has crashed.
One way to make it feasible is to specify assumptions of use. This allows to identify parts of the functionality provided by the kernel and exclude them. Disabling features helps too. It is also possible to pass the blame, e.g. assume that the firmware behaves properly and that the device tree is created properly - so those things you as a downstream have to make sure are certified separately.
Safe update of firmware blobs in bootloader stack
Marek Vasut, Consultant
This talk was a full-length discussion of Marek’s lightning talk at FOSDEM about the same subject.
The bootloader stack is everything that runs from power-on until the operating system takes over. It used to be something simple that ran from parallel NOR, then it became U-Boot. But nowadays there are many additional things done during boot. First of all, the Boot ROM loads a first-stage bootloader, then other things need to be loaded, like the secure environment OS (e.g. OP-TEE), system firmware, firmware for additional cores (safety core, power management), firmware for some peripherals (DDR, thunderbolt). The boot process is also no longer linear, some firmwares stay active after the following stage takes over and there are privilege levels to make sure there is no interference. E.g. EL3 for the secure monitor. There are standard ABIs to switch between the priviledge levels, using an exception instruction and return, e.g. SMC for EL3 and HVC for EL2 (hypervisor).
A standard ABI is required for updates. Indeed, suppose the kernel alone is updated and it expects a newer bootloader/kernel ABI: it will fail to boot. In that case, a recovery mechanism could still save the day. But if the bootloader was updated to a version implementing the new ABI, no recovery would be possible in case of errors. The solution is to insert a component in the boot process that does not have any ABI (does not stay resident) and is not updated, but does support a recovery mechanism. In fact, this piece already exists: after Boot ROM, the CPU runs either U-Boot SPL or TF-A (Trusted Firmware-A). Marek chose SPL because it is much more manageable and more secure than TF-A.
An advantage of U-Boot SPL is that all the drivers are already implemented in U-Boot anyway. The only thing to check is if the driver is using SMCI (i.e relies on previously loaded firmware) - in that case it has to be replaced with direct register writes. The SPL needs a driver to initialize the RAM, but this is similar to other chips and the existing (TF-A) code can be used as inspiration as well. This way, Marek was able to implement SPL for STM32MP13xx with just a few patches.
Keep in mind SPL runs from SRAM and so is constrained to a very small size. There is no protection against stack overflow. Get DEBUG_UART working as soon as possible, it is the most powerful debugging tool available. Then find a way to easily compile and run the SPL, e.g. using DFU upload or OpenOCD.
The idea is to eliminate TF-A entirely, so it is also necessary to replace all PSCI/SMCI calls from U-Boot proper, because the PSCI/SMCI implementations will run only after U-Boot. But the replacement was mostly already needed for the SPL.
The next step is starting OP-TEE-OS, the library/runtime part of OP-TEE. On ARMv7-A, this is easy, just load the right file at the right address, set up the parameters in registers, and jump to the OP-TEE-OS address. One of the parameters is lr, the return address when OP-TEE-OS initialization is finished. Before the jump, you are still at EL3. At the end it will perform a return-from-exception that drops into EL2. We can actually directly jump to the kernel from that point. To make sure the addresses and registers are set up correctly, Marek chose to use a FIT image.
A FIT image is organized as a Devicetree, i.e. using DTS syntax in the source and (modified) DTB to generate the image itself. One of the nodes is called “configurations”, which contains any number of configurations and a reference to a default one. Each configuration refers to a number of images to use for kernel, DTB, initramfs. An image type already exists for OP-TEE-OS in fitImage, so it is enough to include it as a loadable in the image. However, the loader code was actually written for ARMv8, so it had to be modified to insert some glue code that sets up the registers correctly. The new code calls OP-TEE-OS instead of jumping to the kernel when bootm is called.
Before jumping to OP-TEE-OS, we need to set up the TrustZone firewalls correctly, which is normally done by TF-A. That functionality needs to be ported as well.
Because U-Boot has supported A/B updates since forever, reliable updates are possible, at least if full U-Boot is used. U-Boot is a big thing and it runs at a high privilege level, so the risk of security issues is high and therefore U-Boot needs updates. To mitigate that risk, the Falcon mode can boot a fitImage directly from SPL. Since SPL is much smaller, a lot of things are hard-coded instead of flexible, e.g. the location of the fitImage.
AI-Accelerated Development: Practical Applications for Embedded Systems Engineers
Christophe Conil, Save-My-Planet.org
Save-my-planet.org has as a goal to develop smart home products that halve the household electricity consumption without compromising on comfort. It uses open source hardware. This project brings together many different specialised topics, its volunteer developers aren’t specialists in all of them. AI helps them to arrive at a working solution with reasonable development effort.
The talk was mainly a demonstration of one specific system, Claude. Christophe shows how Claude helps him solve various programming problems. It was a very convincing demonstration for people who are willing to see the merit of AI but stay critical. In particular, Christophe shows how Claude can’t replace the developer, but can assist in being more productive.
A summary of the talk can’t give it enough credit, so please watch the video instead!
There were many skeptical but also insightful questions from the audience, and some discussion between audience members. One question that stood out is the question of AI’s energy consumption. In Christophe’s evaluation, the value created by the LLM is high enough that the energy that he would consume himself to take the time to get the same results is much higher than the energy consumed by the LLM.